Curación de contenidos es un barbarismo
por anglicismo acuñado por profesionales del mundo del marketing,
aunque actualmente ha sido adoptado por otros campos, que surge gracias a
la necesidad adquirida que las empresas y profesionales del marketing
tienen de localizar, filtrar, modificar y distribuir, de forma
segmentada, parte de la gran cantidad de contenidos que se generan en
Internet.
Se trata de una nueva tendencia que ha surgido en el seno de las
estrategias de marketing de contenidos que las empresas han incorporado,
recientemente, a sus planes de marketing 2.0, para cubrir las
necesidades que algunos buscadores de contenido en Internet, tales como
Google, les han ido imponiendo, con el fin, de hacer que la información
que aportan los sitios web, vaya adquiriendo valor por sus contenidos,
de forma que los usuarios adquieran experiencias de máxima calidad
mientras "navegan" por Internet, en su incesante búsqueda de
información.
Con el tiempo, la diversidad de internet hizo que la curación de
contenidos se adoptara como una metodología pasible de ser aplicada a
otros campos. Propulsada por la curiosidad, la audacia, la diversión y
el manejo convergente de diferentes disciplinas, la curación de
contenidos se convirtió en una de las llamadas "profesiones invisibles"
que emergieron con la cultura de la interacción. En la actualidad es un
perfil profesional muy buscado y con una gran proyección, que consiste
en la aplicación del "pensamiento algorítmico" para la búsqueda,
selección, clasificación, organización y orientación de contenidos en
función de objetivos empresariales, pero también institucionales y
sociales.
Historia
La Curación de Contenidos no es un fenómeno nuevo, aunque su
aplicación en las estrategias de marketing del ámbito empresarial, si es
muy reciente. Históricamente, museos y galerías de arte han utilizado
esta técnica para seleccionar y exponer sus obras de la forma mas
ordenada y segmentada posible.
Metodología
Filtrado: Método por el cual se filtra la información relacionada con
un tema determinado. El filtrado es necesario, dada la gran cantidad de
información de la que hoy en día disponemos, gracias al fenómeno de
Internet.
Análisis: Tras el método de filtrado, hay que analizar los contenidos
recopilados, para, finalmente, proceder con la elección y modificación
de aquellos contenidos que hayan sido seleccionados.
Distribución: Una vez que hemos seleccionado y modificado los
contenidos de interés para una audiencia determinada, será necesaria la
distribución del resultado final, de forma inteligente y a través de
aquellos canales de interés, para que las búsquedas relacionadas con el
contenido en cuestión, sean efectivas y alcancen la audiencia
seleccionada.
Herramientas
Existen en la actualidad numerosas herramientas que facilitan la
curación de contenidos y que ponen esta disciplina a disposición de
cualquiera que tenga interés en ponerla en práctica. Normalmente es una
práctica muy extendida dentro del mundo empresarial, si bien, cada día
mas, usuarios de Internet, utilizan esta técnica para hacer un uso de la
información más eficiente.
Paper.li selecciona automáticamente los contenidos con las palabras
clave que selecciones y crea fácilmente una publicación digital que se
difundirá a través de redes sociales.
Storify permite extraer contenido de la propia aplicación, así como
de Twitter, Facebook, Google Plus, YouTube, Flickr, Instagram, Google,
App.net, Breaking News, Chute, Giphy, SoundCloud, Gil, Zemanta, Disqus,
GetGlue, StockTwits, Tumblr, RSS o insertando una url en el buscador
general.
Symbaloo organiza todos tus contenidos online de una manera fácil para navegar por internet.
Scoop.it es una herramienta para reunir información, mostrarla y
compartirla en Internet. También en al ámbito educativo se está
utilizando el término curación de contenidos, para hacer referencia a la
tarea de: buscar fuentes de información confiables, filtrarlas y
difundirlas. Podemos usar este recurso en las clases para exponer
trabajos de los alumnos sobre un tema en diversos formatos.
Pinterest permite la creación de tableros sobre temas específicos. A
estos tableros se pueden ir incorporando todo tipo de imágenes, vídeos,
denominados pines que enlazan con la URL y una imagen.
Saludos quisiera comentarle mi experiencia con Google Academico.
de primera instancia obtuve buenos resultados en la búsqueda compare los resultado con el buscador principal "Google" y me arrojo mejor resultado el Google Académico en lo que respecta a información académica libros, ensayos, textos informativos y demás, es una buena herramienta de Google que yo desconocía, aunado a eso obtuve mejores resultados utilizando la búsqueda avanzada con la estrategia formulada en el curso.
Me gusto tanto esta herramienta que empecé a indagar en los complementos de Mozilla Firefox y he encontrado uno que se adapta a mis necesidades solo tecleo el icono y se despliega una ventana donde puedo colocar lo que deseo buscar en dicho navegador.
Les dejo el link del complemento por si desean instalarlo
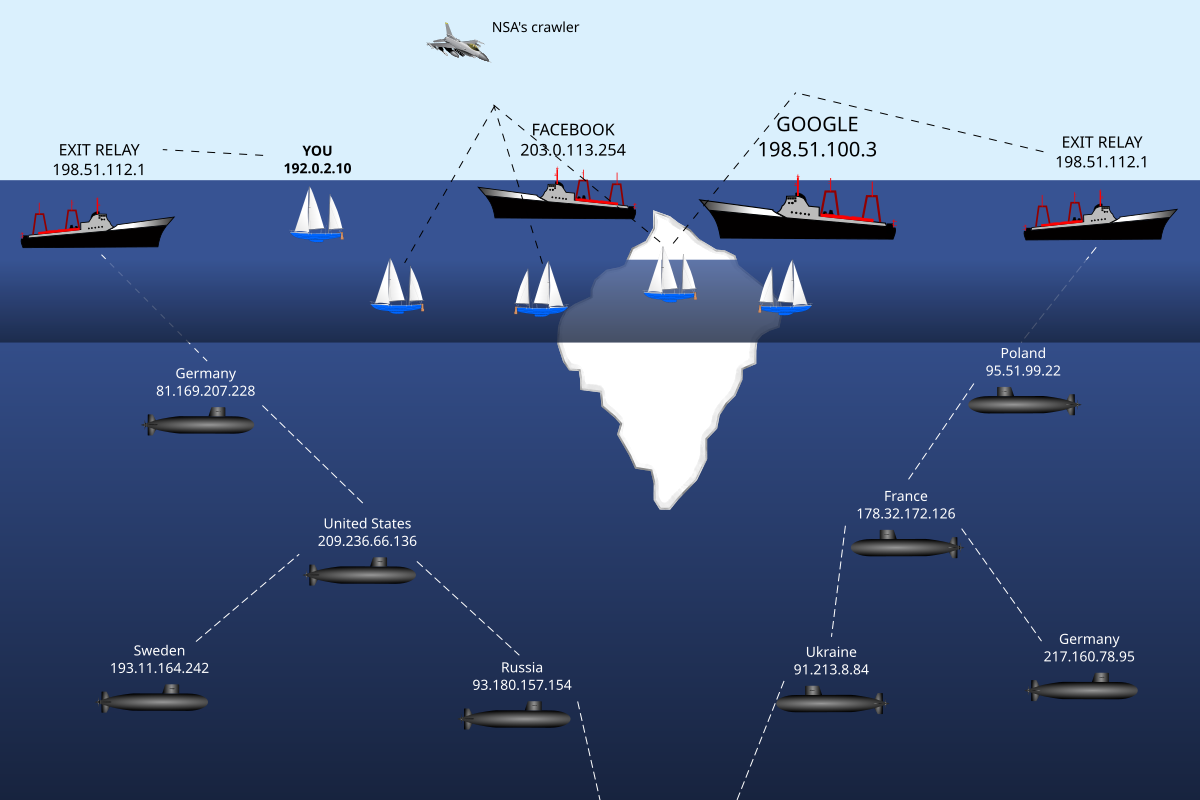
Se conoce como Internet superficial a la porción de Internet que es indexada por las arañas de los motores de búsqueda. La parte que no es indexada se conoce como Internet profunda
Las arañas de los buscadores van recorriendo las páginas web,
almacenando información que contienen y buscando enlaces a otros sitios
web para seguir actualizando sus bases de datos. Con el tiempo acaban
recorriendo todas las páginas de Internet que tienen enlaces desde
otras. Pero por distintos motivos (enlaces generados por JavaScript y Flash,
páginas protegidas con contraseña, fichero de exclusión de robots,
etc.) algunas páginas no pueden ser alcanzadas por las arañas de los
buscadores. Estas páginas forman la Internet Profunda.
En enero de 2005, según un estudio reciente que investigó distintos motores de búsqueda (Google, MSN, Yahoo y Ask Jeeves) se determinó que había 11.500 millones de páginas web en los índices de los buscadores.
En junio de 2008 los índices contenían más de 63.000 millones de páginas Web.
Web Profunda
Se conoce informalmente como internet profunda o internet invisible a una porción presumiblemente muy grande de la internet que es difícil de rastrear o ha sido hecha casi imposible de rastrear y deliberadamente, como lo es el caso del Proyecto Tor, el cual fue creado de esta manera por medio de métodos poco convencionales, como con la proxyficación con muchos proxys, el no utilizar direcciones de internet, sino códigos, y el pseudodominio de nivel superior .onion, el cual fue creado por la Armada de los Estados Unidos como una prueba y ahora es aprovechada por delincuentes cibernéticos.
En idioma inglés recibe varios nombres:
Deepweb (internet profunda).
Invisible Web (internet invisible).
Deep Web (internet profunda).
Dark Web (internet oscura).
Hidden Web (internet oculta).
Se conoce así a todo el contenido de internet que no forma parte de la internet superficial, es decir, de las páginas indexadas por las redes de los motores de búsqueda
de la red. Esto se debe a las limitaciones que tienen las redes para
acceder a todos los sitios web por distintos motivos. La mayor parte de
la información encontrada en la internet profunda está enterrada en
sitios generados dinámicamente y para los motores de búsqueda
tradicionales es difícil hallarla. Fiscales y agencias gubernamentales
han calificado a la internet profunda como un refugio para la
delincuencia debido al contenido ilícito que se encuentra en ella
La principal causa de la existencia de la internet profunda es la imposibilidad de los motores de búsqueda (Google, Yahoo, Bing,
etc.) de encontrar o indexar gran parte de la información existente en
internet. Si los buscadores tuvieran la capacidad para acceder a toda la
información entonces la magnitud de la «internet profunda» se reduciría
casi en su totalidad. No obstante, aunque los motores de búsqueda
pudieran indexar la información de la internet profunda esto no
significaría que esta dejará de existir, ya que siempre existirán las
páginas privadas. Los motores de búsqueda no pueden acceder a la
información de estas páginas y solo determinados usuarios, aquellos con
contraseña o códigos especiales, pueden hacerlo.
Los siguientes son algunos de los motivos por los que los buscadores son incapaces de indexar la internet profunda:
Páginas y sitios web protegidos con contraseñas o códigos establecidos.
Páginas que el buscador decidió no indexar: esto se da generalmente
porque la demanda para el archivo que se decidió no indexar es poca en
comparación con los archivos de texto HTML; estos archivos generalmente también son más «difíciles» de indexar y requieren más recursos.
Sitios que, dentro de su código, tienen archivos que le impiden al buscador indexarlo.
Documentos en formatos no indexables.
Según la tecnología usada por el sitio: por ejemplo los sitios que
usan bases de datos. Para estos casos los buscadores pueden llegar a la
interfaz creada para acceder a dichas bases de datos, como por ejemplo,
catálogos de librerías o agencias de gobierno.
Enciclopedias, diccionarios, revistas en las que para acceder a la
información hay que interrogar a la base de datos, como por ejemplo la
base de datos de la RAE.
Sitios que tienen una mezcla de medios o archivos que no son fáciles de clasificar como visible o invisible (Web opaca).
La información es efímera o no suficientemente valiosa para indexar.
Es posible indexar está información pero como cambia con mucha
frecuencia y su valor es de tiempo limitado no hay motivo para
indexarla.
Páginas que contienen mayormente imágenes, audio o video con poco o nada de texto.
Los archivos en formatos PostScript, Flash, Shockwave, ejecutables (.exe), archivos comprimidos (.zip,.rar, etc).
Información creada en páginas dinámicas después de llenar un formulario, la información detrás de los formularios es invisible.
Documentos dinámicos, son creados por un script que selecciona datos
de diversas opciones para generar una página personalizada. Este tipo
de documentos, aunque sí se pueden indexar, no están en los motores de
búsqueda porque en ocasiones puede haber varias páginas iguales, pero
con pequeños cambios, y las arañas web quedan atrapadas en ellos.
Es un sitio aislado, es decir, no hay ligas que lo vinculen con otros sitios y viceversa.
Son subdirectorios o bases de datos restringidas.
La internet profunda es un conjunto de sitios web y bases de datos
que buscadores comunes no pueden encontrar ya que no están indexadas. El
contenido que se puede hallar dentro de la internet profunda es muy
amplio.
Se estima que la internet profunda es 500 veces mayor que la internet superficial, siendo el 95 % de esta información públicamente accesible.
En 2010 se estimó que la información que se encuentra en la internet profunda es de 7500 terabytes,
lo que equivale a aproximadamente 550 billones de documentos
individuales. El contenido de la internet profunda es de 400 a 550 veces
mayor de lo que se puede encontrar en la internet superficial. En
comparación, se estima que la internet superficial contiene solo 19
terabytes de contenido y un billón de documentos individuales.
También en 2010 se estimó que existían más de 200 000 sitios en la internet profunda.
Estimaciones basadas en la extrapolación de un estudio de la
Universidad de California en Berkeley especula que actualmente la
internet profunda debe tener unos 91 000 Terabytes.
La Association for Computing Machinery (ACM) publicó en 2007 que Google y Yahoo
indexaban el 32 % de los objetos de la internet profunda, y MSN tenía
la cobertura más pequeña con el 11 %. Sin embargo, la cobertura de lo
tres motores era de 37 %, lo que indicaba que estaban indexando casi los
mismos objetos.
Se prevé que alrededor del 95 % del internet es internet profunda,
también le llaman invisible u oculta, la información que alberga no
siempre está disponible para su uso. Por ello se han desarrollado
herramientas como buscadores especializados para acceder a ella.
La Web profunda se refiere a la colección de sitios o bases de datos que un buscador común, como Google,
no puede o quiere indexar. Es un lugar específico del internet que se
distingue por el anonimato. Nada que se haga en esta zona puede ser
asociado con la identidad de uno, a menos que uno lo deseé.
Bergman, en un artículo semanal sobre la Web profunda publicado en el Journal of Electronic Publishing,
mencionó que Jill Ellsworth utilizó el término «Web invisible» en 1994
para referirse a los sitios web que no están registrados por algún motor
de búsqueda.
En su artículo, Bergman citó la entrevista que Frank García hizo a Ellsworth en 1996:
Sería un sitio que, posiblemente esté diseñado razonablemente, pero
no se molestaron en registrarlo en alguno de los motores de búsqueda.
¡Por lo tanto, nadie puede encontrarlos! Estás oculto. Yo llamo a esto
la Web invisible.
Otro uso temprano del término Web Invisible o web profunda fue
por Bruce Monte y Mateo B. Koll de Personal Library Software, en una
descripción de la herramienta @ 1 de web profunda, en un comunicado de
prensa de diciembre de 1996.
La importancia potencial de las bases de datos de búsqueda también se
reflejó en el primer sitio de búsqueda dedicado a ellos, el motor AT1
que se anunció con bombos y platillos a principios de 1997. Sin embargo,
PLS, propietario de AT1, fue adquirida por AOL en 1998, y poco después el servicio AT1 fue abandonado.
El primer uso del término específico de web profunda, ahora generalmente aceptada, ocurrió en el estudio de Bergman de 2001 mencionado anteriormente.
Por otra parte, el término web invisible se dice que es inexacto porque:
Muchos usuarios asumen que la única forma de acceder a la web es consultando un buscador.
Alguna información puede ser encontrada más fácilmente que otra, pero esto no quiere decir que esté invisible.
La web contiene información de diversos tipos que es almacenada y recuperada en diferentes formas.
El contenido indexado por los buscadores de la web es almacenado
también en bases de datos y disponible solamente a través de las
interrogaciones del usuario, por tanto no es correcto decir que la
información almacenada en bases de datos es invisible.
RASTREANDO LA WEB PROFUNDA
Los motores de búsqueda comerciales han comenzado a explorar métodos
alternativos para rastrear la Web profunda. El Protocolo del sitio
(primero desarrollado e introducido por Google
en 2005) y OAI son mecanismos que permiten a los motores de búsqueda y
otras partes interesadas descubrir recursos de la internet profunda en
los servidores web en particular. Ambos mecanismos permiten que los
servidores web anuncien las direcciones URL
que se puede acceder a ellos, lo que permite la detección automática de
los recursos que no están directamente vinculados a la Web de la
superficie.El sistema de búsqueda de la Web profunda de Google
pre-calcula las entregas de cada formulario HTML
y agrega a las páginas HTML resultantes en el índice del motor de
búsqueda de Google. Los resultados surgidos arrojaron mil consultas por
segundo al contenido de la Web profunda.17 Este sistema se realiza utilizando tres algoritmos claves:
La selección de valores de entrada, para que las entradas de búsqueda de texto acepten palabras clave.
La identificación de los insumos que aceptan solo valores específicos (por ejemplo, fecha).
La selección de un pequeño número de combinaciones de entrada que
generan URLs adecuadas para su inclusión en el índice de búsqueda Web.
Métodos de profundización
Las arañas (Web crawler)
Cuando se ingresa a un buscador y se realiza una consulta, el
buscador no recorre la totalidad de internet en busca de las posibles
respuestas, sino que busca en su propia base de datos, que ha sido
generada e indizada previamente. Se utiliza el término «araña web» (en inglés web crawler)
o robots (por software, comúnmente llamados "bots") inteligentes que
van haciendo búsquedas por enlaces de hipertexto de página en página,
registrando la información ahí disponible.
El contenido que existe dentro de la internet profunda es en muy
raras ocasiones mostrado como resultado en los motores de búsqueda, ya
que las «arañas» no rastrean bases de datos ni los extraen. Las arañas
no pueden tener acceso a páginas protegidas con contraseñas, algunos
desarrolladores que no desean que sus páginas sean encontradas insertan
etiquetas especiales en el código para evitar que sea indexada. Las
«arañas» son incapaces de mostrar páginas que no estén creadas en
lenguaje HTML, ni tampoco puede leer enlaces que incluyen un signo de interrogación. Pero ahora sitios web no creados con HTML
o con signos de interrogación están siendo indexados por algunos
motores de búsqueda. Sin embargo, se calcula que incluso con estos
buscadores más avanzados solo se logra alcanzar el 16% de la información
disponible en la internet profunda. Existen diferente técnicas de
búsqueda para extraer contenido de la internet profunda como librerías
de bases de datos o simplemente conocer el URL al que quieres acceder y escribirlo manualmente.
Tor
The Onion Router (abreviado como TOR) es un proyecto diseñado e
implementado por la marina de los Estados Unidos lanzado el 20 de
septiembre de 2002. Posteriormente fue patrocinado por la EFF
(Electronic Frontier Foundation, una organización en defensa de los
derechos digitales). Actualmente subsiste como TOR Project, una
organización sin ánimo de lucro galardonada en 2011 por la Free Software
Foundation por permitir que millones de personas en el mundo tengan
libertad de acceso y expresión en internet manteniendo su privacidad y
anonimato
A diferencia de los navegadores de internet convencionales, Tor le
permite a los usuarios navegar por la Web de forma anónima. Tor es
descargado de 30 millones a 50 millones de veces al año, hay
0,8 millones de usuarios diarios de Tor y un incremento del 20 %
solamente en 2013. Tor puede acceder a unos 6500 sitios web ocultos.
Cuando se ejecuta el software de Tor, para acceder a la internet
profunda, los datos de la computadora se cifran en capas. El software
envía los datos a través de una red de enlaces a otros equipos ―llamados
en inglés «relays» (‘nodos’)― y lo va retransmitiendo quitando
una capa antes de retransmitirlo de nuevo, esta trayectoria cambia con
frecuencia. Tor cuenta con más de 4000 retransmisiones y todos los datos
cifrados pasan a través de ―por lo menos― tres de estos relays. Una vez
que la última capa de cifrado es retirado por un nodo de salida, se
conecta a la página web que desea visitar.
El contenido que puede ser encontrado dentro de la internet profunda
es muy vasto, se encuentran por ejemplo, datos que se generan en tiempo
real, como pueden ser valores de Bolsa, información del tiempo, horarios
de trenes; bases de datos sobre agencias de inteligencia, desidentes
políticos y contenidos criminales.
Bitcoin
Mercados ilegales están alojados en servidores que son exclusivos
para usuarios de Tor. En estos sitios, se pueden encontrar drogas,
armas, o incluso asesinos a sueldo. Se utiliza la moneda digital llamada
Bitcoin, que tiene sus orígenes en 2009, pero que se ha vuelto todo un fenómeno desde 2012,
que se intercambia a través de billeteras digitales entre el usuario y
el vendedor, lo que hace que sea prácticamente imposible de rastrear.
Existen muchos mitos acerca de la internet profunda. La internet
profunda no es una región prohibida o mística de internet, y la
tecnología relacionada con ella no es malévola. Ya que en ella también
se alberga lo que ahora se conoce como AIW (Academic Invisible Web:
‘internet académica invisible’ por sus siglas en inglés) y se refiere a
todas las bases de datos que contienen avances tecnológicos,
publicaciones científicas, y material académico en general
Los recursos de la internet profunda pueden estar clasificados en las siguientes categorías:
contenido de acceso limitado: los sitios que limitan el acceso a sus páginas de una manera técnica (Por ejemplo, utilizando el estándar de exclusión de robots o captcha, que prohíben los motores de búsqueda de la navegación por y la creación de copias en caché.
contenido dinámico: las páginas dinámicas que devuelven
respuesta a una pregunta presentada o acceder a través de un formulario,
especialmente si se utilizan elementos de entrada en el dominio abierto
como campos de texto.
contenido no enlazado: páginas que no están conectadas con otras páginas, que pueden impedir que los programas de rastreo web tengan acceso al contenido. Este material se conoce como páginas sin enlaces entrantes.
contenido programado: páginas que solo son accesibles a través de enlaces producidos por JavaScript, así como el contenido descargado de manera dinámica a partir de los servidores web a través de soluciones de Flash o Ajax.
sin contenido HTML:
contenido textual codificado en multimedia (imagen o video) archivos o
formatos de archivo específicos no tratados por los motores de búsqueda.
web privada: los sitios que requieren de registro y de una contraseña para iniciar sesión
web contextual: páginas con contenidos diferentes para diferentes contextos de acceso (por ejemplo, los rangos de direcciones IP de clientes o secuencia de navegación anterior).
Seudodominio de nivel superior
Un pseudodominio de nivel superior o Pseudo-TLD (del inglés Pseudo-Top Level Domain) son términos usados para identificar servicios en redes de computadores que no participan en el sistema oficial del sistema de nombres de dominio (DNS) pero que usan una jerarquía y una nomenclatura similar a como lo hacen los TLDs
verdaderos. Son usados sólo para propósitos especiales, típicamente
para direccionar máquinas que no son alcanzables directamente usando el protocolo IP.
Aunque no tienen un estatus oficial, son consideradas como una forma de identificación de este tipo de servicios.
Debido a su naturaleza la mayoría de los Pseudo-TLD tienen un periodo de vida corto aunque hay algunas excepciones y muchos sobreviven como reliquias.
Ejemplos: .bitnet para Bitnet, .onion para servicios de la red Tor, .garlic para servicios de la red i2p, .csnet para CSNET, .swift para el SWIFTNet Mail y .uucp para servicios de la red Usenet.
Todos conocemos a Google y lo usamos con
gran entusiasmo. Pero uno de los grandes desconocidos a la hora de
exprimir el todo poderoso buscador son los comandos o los operadores de búsqueda en Google.
Ahora mismo puede que te estés preguntando ¿qué es eso de un operador de búsqueda en Google o comando?
En realidad, no son más que unas simples
instrucciones que incluyes en tus peticiones de búsqueda en la cajita
del buscador para refinar los resultados de nuestra búsqueda y que te
sirven para obtener una mayor precisión, sin necesidad de usar la
búsqueda avanzada.
Es como si utilizaras una serie de recetas para obtener un resultado mucho más enriquecido y en menos tiempo.
Por eso hoy en esta entrada, quiero
mostrarte hasta XX operadores de búsqueda en Google con los que refinar
tus búsquedas de forma fácil y muy sencilla. Para que tengas un
recetario con el que construir tus propias búsquedas cuando lo
necesites.
Si te pica la curiosidad sigue leyendo. Esto te va a gustar.
Descubre los mejores operadores de búsqueda en Google
Tenemos varios tipos de operadores de búsqueda en Google:
los operadores booleanos basados en el álgebra de boole
los operadores o comandos básicos
los operadores específicos de búsqueda en una página web
los operadores de búsqueda basados especiales
y los operadores de búsqueda para matemáticos
En realidad no existe una clasificación oficial de operadores de búsqueda para Google pero yo los he clasificado de esta manera.
Simplemente para agruparlos y hacer más sencilla la lectura de esta entrada.
En cualquier caso estos son todos los operadores que puedes usar y combinar para crear tus búsquedas o alertas en Google Alerts para obtener mayor precisión de búsqueda.
1-.# Operadores de búsqueda en Google booleanos
Operador OR: crisis OR depresión
Sirve para buscar paginas que contengan al menos una de las palabras.
Operador -: crisis -económica
Sirve para excluir páginas donde aparezca el termino precedido de signo -.
Operador ” “: “crisis económica en España”
Sirve para mostrar las páginas donde aparece el termino exacto entrecomillado.
Operador *: “crisis * en España”
Sirve como comodín para completar las búsquedas cuando no sabemos bien que buscamos.
2-.# Operadores de búsqueda en Google o comandos básicos
Operador define: define:procrastinar
Sirve para buscar la definición de cualquier palabra que desconozcamos
Operador site: termino site:www.elmundo.es
Sirve para buscar en una página web determinada o concreta un termino o palabra clave
Operador info: info:www.elmundo.es
Sirve para obtener información a cerca
de una pagina web como por ejemplo la versión en cache almacenada,
páginas similares o páginas que redirigan al sitio web en cuestion
Operador related: related:www.elmundo.es
Sirve para localizar sitios web similares a la dirección url que has solicitado
Operador link: link:www.elmundo.es
Sirve para localizar las paginas web que tienen enlace diriguidos a una pagina determinada
Operador cache: cache:www.elmundo.es
Sirve para comprobar como era la pagina la última vez que el bot de Google indexo esa página web.
Operador filetype: filetype:pdf plan de marketing
Sirve para localizar paginas que contenga archivos ppt, pdf, xls, doc etc… relacionados con un termino o palabra calve
3-.# Operadores de búsqueda en Google para partes específicas de una web
Operador inurl o allinurl: inurl:”vehiculos de ocasión” allinurl:vehículos de ocasión
Sirve para detectar las páginas
que contienen cualquiera de los términos empleados en la url y se puede
combinar con otros operadores de búsqueda
Operador allinanchor o inanchor: allinanchor:”seguros de coche baratos”
Sirve para localizar páginas web con un texto ancla enlazado que coincida con nuestro término de búsqueda.
Operador allintext o intext: allintext:”promocion de viviendas”-madrid
Sirve para localizar páginas webs que contengan en su texto el termino de búsqueda deseado
Operador allintitle o intitle: allintitle:”vacaciones en la playa”
Sirve para encontrar páginas web con el termino de búsqueda que aparezca en el título del texto
4-.# Operdores de búsqueda en Google especiales
Operador @: @coche, @banco @libro
Sirve para buscar o encontrar etiquetas sociales asociadas con twitter ej. @nombre
Operadores de la búsqueda de Google que ya no están operativos.
Operador ~: términos similares
Este operador ahora deshabilitado por
Google era muy útil. Servia para devolverte resultados con términos y
palabras claves similares relacionadas con tu búsqueda. Era un operador
muy versátil y estupendo para hacer búsquedas en campos de actividad que
no dominabas para localizar otros términos e informaciones
relacionadas.
Operador +: añadir palabras o términos en la búsqueda
En realidad el operador + se usaba para
añadir obligatoriamente un termino a tu búsqueda. Hoy día se puede
emplear como un operador matemático o como hemos visto como un operador
para identificar cuentas de Google+. Reconozco que este no es un
operador que haya utilizado mucho cuando todavía estaba operativo pero
que que si es de utilidad, puesto que podríamos usarlo como opuesto al
operador – para excluir términos en tus búsquedas.
Aprende a usar los operadores de búsqueda en Google correctamente
Lo mejor para dominar los operadores de búsqueda en Google que hemos visto es practicar y ver los resultados.
Para ello combina y juega con los
operadores y analiza los resultados que obtienes. Cuando obtengas una
búsqueda que realmente te guste guárdala creando una alerta en el
servicio de alertas de Google llamado “Google Alerts”
Nunca se termina de dominar o crear una búsqueda perfecta. Pero la práctica lleva a la perfección.
Bonus Tip: siempre
que hagas una búsqueda utiliza el navegador en modo incógnito así evitas
que los resultados que obtienes estén contaminados por tu historial de
navegación y búsquedas.
Si estas interesado en seguir dominando a Google, no te olvides de echar un vistazo a nuestra guía definitiva para buscar en Google y practicar lo que te contamos en ella.
El primer buscador fue "Wandex", un índice (ahora desaparecido) realizado por la World Wide Web Wanderer, un robot desarrollado por Mattew Gray en el MIT, en 1993. Otro de los primeros buscadores, Aliweb, también apareció en 1993 y todavía está en funcionamiento. El primer motor de búsqueda de texto completo fue WebCrawler,
que apareció en 1994. A diferencia de sus predecesores, éste permitía a
sus usuarios una búsqueda por palabras en cualquier página web, lo que
llegó a ser un estándar para la gran mayoría de los buscadores.
WebCrawler fue asimismo el primero en darse a conocer ampliamente entre
el público. También apareció en 1994 Lycos (que comenzó en la Carnegie Mellon University).
Muy pronto aparecieron muchos más buscadores, como Excite, Infoseek,
Inktomi, Northern Light y Altavista. De algún modo, competían con
directorios (o índices temáticos) populares tales como Yahoo!. Más
tarde, los directorios se integraron o se añadieron a la tecnología de
los buscadores para aumentar su funcionalidad.
Antes del advenimiento de la Web, había motores de búsqueda para otros protocolos o usos, como el buscador Archie, para sitios FTP anónimos y el motor de búsqueda Verónica, para el protocolo Gopher.
Con la llegada de Google,
el modo en que los motores de búsqueda funcionaban cambió de forma
radical, democratizando los resultados que se ofrecen en su buscador.
Google basó el funcionamiento de su motor de búsqueda en la relevancia
de los contenidos de cada sitio web para los propios usuarios, es decir,
priorizando aquellos resultados que los usuarios consideraban más
relevantes para una temática concreta. Para ello patentó su famoso PageRank, un conjunto de algoritmos que valoraban la relevancia de un sitio web asignándole un valor numérico del 0 al 10.
En la actualidad se aprecia una tendencia por parte de los
principales buscadores de Internet a dar el salto hacia entornos móviles
creando una nueva generación de buscadores: los buscadores móviles
Desea Tener información adicional entra en mi muro colaborativo, allí tendrás toda clase de información relacionada con buscadores y búsqueda en la web, encontraras, conceptos, definiciones, noticias, enlaces a buscadores metabuscadores y demás.
1. ¿Qué es la infoxicación? ¿Es lo mismo la infoxicación y el "overload information"?
La infoxicación es el exceso de información. Es, pues, lo mismo que el
information overload. Es estar siempre "on", recibir centenares de
informaciones cada día, a las que no puedes dedicar tiempo. Es no poder
profundizar en nada, y saltar de una cosa a la otra. Es el "working
interruptus". Es el resultado de un mundo en donde se prima la
exhaustividad ("todo sobre") frente a la relevancia ("lo más
importante").
2. ¿Quiénes son más propensos a ser "infoxicados"?
Los que pretenden que siguiendo todos los inputs que reciben estarán más
informados. No es leer todo lo que está a tu alcance lo que te hace más
informado, sino recibir información de calidad. Los que confunden
cantidad de información con calidad son los más propensos a salir
infoxicados. Estar todo el día conectados a decenas de fuentes confunde
más que informa. La ansiedad por la información infoxica.
3. ¿Cuáles son los efectos de la entrada constante de información y cómo puede afectar el funcionamiento del ser humano?
Demasiada información limita nuestra capacidad para comprender. Para
procesar mucha información hay que saberla dominar. Sólo alguien que ha
profundizado en una materia, que ha leído mucho sobre el tema, puede
procesar rápidamente información: sabe lo que es cierto, lo que es
probablemente cierto, y lo que es obviamente falso. Para procesar con
rapidez información hay que tener mucho conocimiento previo sobre el
tema. Esta es una de las paradojas de nuestra era: no tenemos tiempo de
profundizar en nada, de ser un experto, lo que nos daría capacidad para
manejar rápidamente mucha información; en lugar de ello, procesamos más y
más información antes de convertirnos en expertos en algo. Devenimos
“comepalabras” antes de que podamos saborearlas. Leemos demasiado y
entendemos muy poco de lo que leemos.
4. ¿Cómo una persona puede identificar que está "infoxicado"?
Cuando siente que no puede manejar toda la información que cree que
debería manejar. O sea, cuando la información que le rodea en su día a
día le angustia. Uno está infoxicado cuando no puede absorber más
información, cuando todo lo que hace es remitir la información que
recibe a otros, a sus amigos, a sus contactos en las redes sociales.
Pero hay un síntoma incluso más claro: estás infoxicado cuando te
resulta difícil leer un texto de forma pausada, palabra a palabra;
cuando lees saltando palabras, porque te has acostumbrado a leer así en
diagonal. Estás infoxicado cuando lees sin entender lo que lees.
Mi nombre es Jose Hernandez tengo 32 años de edad, venezolano trabajo como tecnico reparador de pc, tengo conocimientos medio avanzado en informatica, adquiridos durante mi vida mediantes cursos, videos, libros etc. me intereso el curso ya que estoy navegando en la web aprox. 10 horas al dia y me gustaria adquirir una mejor manera de buscar, tengo conomientos medios en diseño web (html, css)